Background
Recognition systems for chemical molecular structures have been widely utilized in various fields, including pharmaceutical research and development, human-computer interaction, biochemistry, and organic synthesis. These systems enable the gathering and organization of millions of chemical molecular structures from academic journals and patents spanning several decades, which improving effciency and convenience in analyzing drug molecular structures.
In addition to this, the recognition of chemical structures also holds significant value in the field of education. For instance, by automatically recognizing handwritten chemical structures in students’ responses, we can develop applications for intelligent grading and analysis, helping children excel in the subject of chemistry. However, the academic community currently does not pay enough attention to the recognition of chemical structures in educational settings. Therefore, we are organizing this competition in the hope of promoting the development of this sub-field.
The objective of the task of chemical structure recognition is to extract the molecular structural formula from the input image into a corresponding graph structure, where the key information includes atoms, chemical bonds, and their interconnections. In educational contexts, we desire that the graph structure reconstructed by the model maintains visual consistency with the image, avoiding abbreviations, omissions, or significant rotations. This is illustrated in Figure 1.
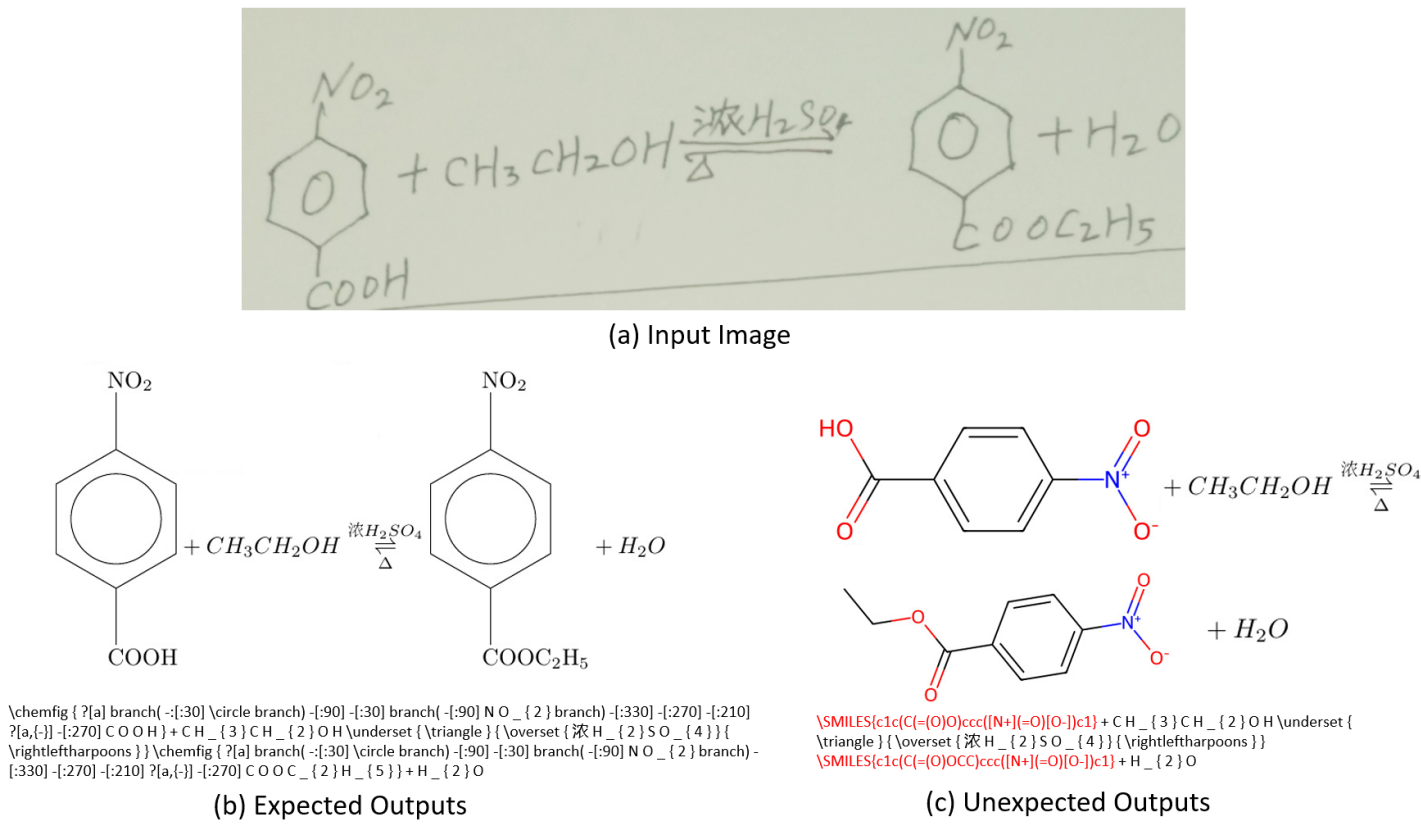
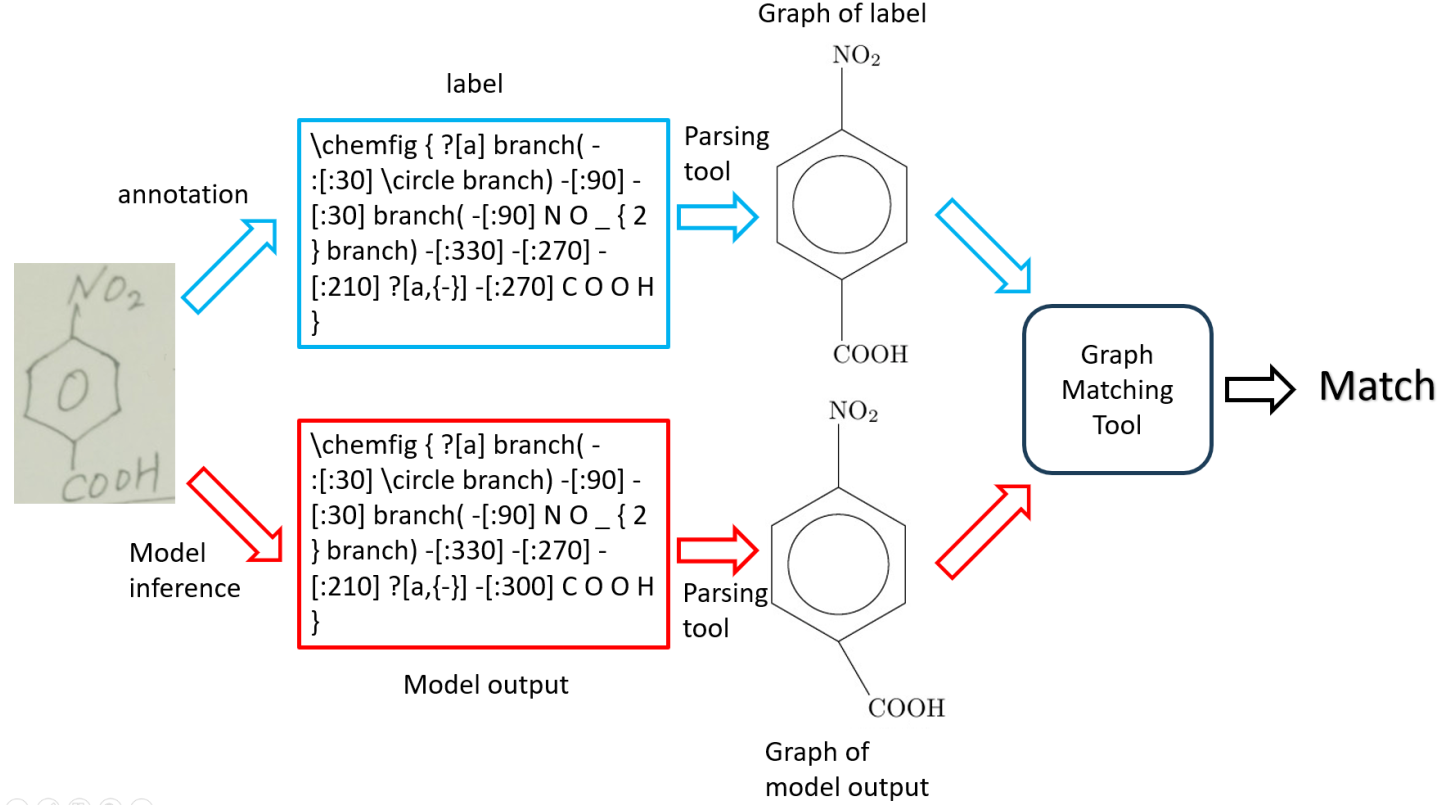
To support the training and evaluation of the aforementioned recognition task, we have provided a comprehensive dataset comprising 49,995 images in training set , 2,991 images in test set A and 7,988 images in testing set B. The images are annotated in the form of strings, but they can be converted into graph structures using the tools we provide, as shown in Figure 2. Participants are required to construct models that output in the specified format, either as strings or graphs. These outputs will then be assessed using our graph comparison tool to evaluate the performance metrics.
Rules
- Participants are supposed to submit the technical report and source code (at least the code used in the inference stage).
- Usage of real-world datasets from any domain is not allowed. However, participants may use synthetic data and pre-trained models as long as the synthetic materials and pre-trained models are publicly available. The final technical report must clearly outline how the data was synthesized and which pre-trained models were used. Dataset submission is not required.
- Participants are not allowed to submit the baseline provided directly.
- One participant is not allowed to join more than one team.
- The top 10 participants in test A phase (excluding any duplicate registrations or invalid teams) will advance to the test B phase. The final score depends on the performance in test B.